ArrayList
ArrayList是线程不安全的
ArrayList和LinkedList对比?
ArrayList底层是数组,查找快
LinkedList底层是链表,插入快
特性
实现了三个标记接口:RandomAccess, Cloneable, java.io.Serializable,它们内部都没有方法和属性
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
1、RandomAccess
支持随机访问(基于下标),为了能够更好地判断集合是ArrayList还是LinkedList,从而能够更好选择更优的遍历方式,提高性能!
RandmoAccess是java中用来被List实现,为List提供快速访问功能的。我们即可以通过元素的序号(下标)快速获取元素对象;这就是快速随机访问。
实现了RandomAccess的标记接口,支持基于下标的方式访问集合
2、Cloneable
支持拷贝:实现Cloneable接口,重写clone方法、方法内容默认调用父类的clone方法。
实现 Cloneable来表示该对象能被克隆,能使用Object.clone()方法。如果没有实现 Cloneable的类对象调用clone()就会抛出CloneNotSupportedException。
2.1、浅拷贝
浅拷贝是指拷贝对象时仅仅copy对象本身和对象中的基本变量,而不拷贝对象包含的引用指向的对象。
基础类型的变量拷贝之后是独立的,不会随着原变量变动而变
String类型拷贝之后也是独立的
引用类型拷贝的是引用地址,拷贝前后的变量引用同一个堆中的对象
public Object clone() throws CloneNotSupportedException {
Study s = (Study) super.clone();
return s;
}
2.2、深拷贝
深拷贝不仅copy对象本身,而且copy对象包含的引用指向的所有对象。
举例:对象X中包含对Y的引用,Y中包含对Z的引用。浅拷贝X得到X1,X1中依然包含对Y的引用,Y中依然包含对Z的引用。深拷贝则是对浅拷贝的递归,深拷贝X得到X1,X1中包含对Y1(Y的copy)的引用,Y1中包含对Z1(Z的copy)的引用。
变量的所有引用类型变量(除了String)都需要实现Cloneable(数组可以直接调用clone方法)接口,clone方法中,引用类型需要各自调用clone,重新赋值
public Object clone() throws CloneNotSupportedException {
Study s = (Study) super.clone();
s.setScore(this.score.clone());
return s;
}
让对象可以被克隆,应具备以下2个条件:
- 让该类实现java.lang.Cloneable接口;
- 重写(Override)Object的clone()方法;
java的传参,基本类型和引用类型传参
基本类型在方法传递参数时,是将变量复制一份,然后传入方法体去执行。复制的是栈中的内容,所以基本类型是复制的变量名和值,值变了不影响原变量。
引用类型复制的是变量名和值(引用地址),对象变了,会影响原变量(引用地址是一样的)
String:是不可变对象,重新赋值时,会在常量表新生成字符串(如果已有,直接取他的引用地址),将新字符串的引用地址赋值给栈中的新变量,因此源变量不会受影响
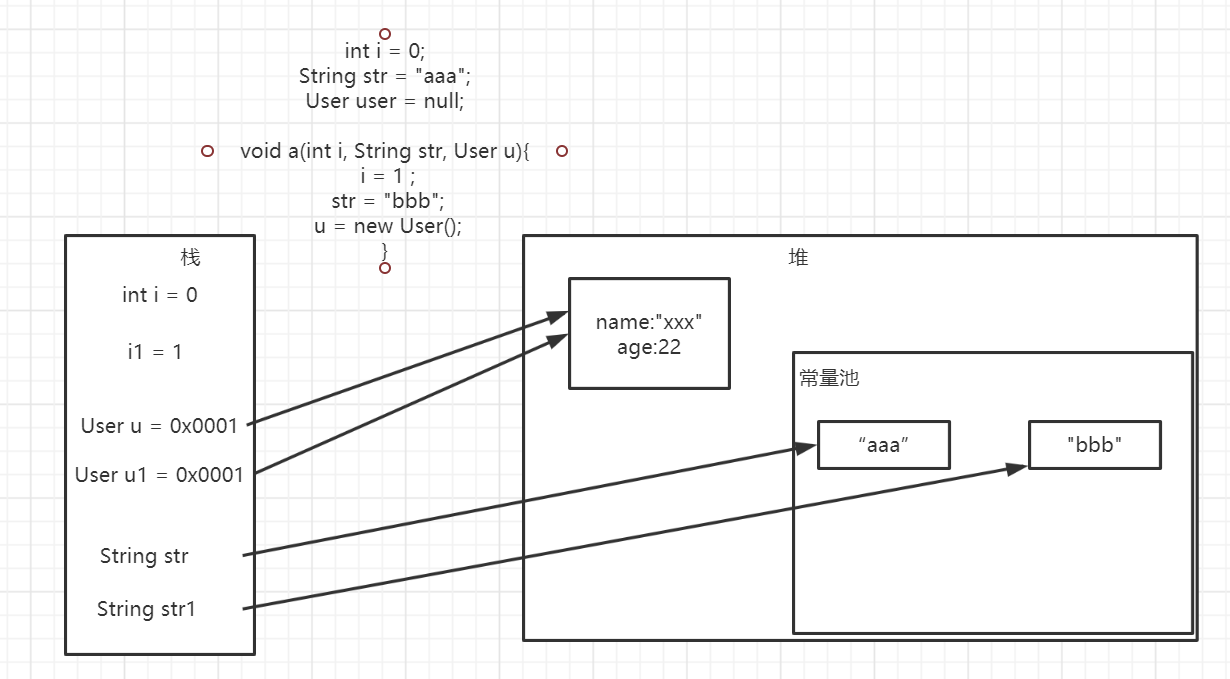
基本类型:值传递 引用类型传值:引用传递 String是一种特殊的值传递
3、Serializable
序列化:将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据,在Java中的这个Serializable接口其实是给jvm看的,通知jvm,我不对这个类做序列化了,你(jvm)帮我序列化就好了。如果我们没有自己声明一个serialVersionUID变量,接口会默认生成一个serialVersionUID,默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常(每次序列化都会重新计算该值)
4、AbstractList
继承了AbstractList ,说明它是一个列表,拥有相应的增,删,查,改等功能。
5、List
为什么继承了 AbstractList 还需要 实现List 接口?
1、在StackOverFlow 中:传送门 得票最高的答案的回答者说他问了当初写这段代码的 Josh Bloch,得知这就是一个写法错误。
I’ve asked Josh Bloch, and he informs me that it was a mistake. He used to think, long ago, that there was some value in it,
but he since “saw the light”. Clearly JDK maintainers haven’t considered this to be worth backing out later.
基本属性
private static final long serialVersionUID = 8683452581122892189L;//序列化版本号(类文件签名),如果不写会默认生成,类内容的改变会影响签名变化,导致反序列化失败
private static final int DEFAULT_CAPACITY = 10;//如果实例化时未指定容量,则在初次添加元素时会进行扩容使用此容量作为数组长度
//static修饰,所有的未指定容量的实例(也未添加元素)共享此数组,两个空的数组有什么区别呢? 就是第一次添加元素时知道该 elementData 从空的构造函数还是有参构造函数被初始化的。以便确认如何扩容。空的构造器则初始化为10,有参构造器则按照扩容因子扩容
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData; // arrayList真正存放元素的地方,长度大于等于size
private int size;//arrayList中的元素个数
数组长度一经确认,长度不可变
数组是一块连续的内存区域,存储相同类型的元素,使用下标访问。每一个元素占用的内存空间是相同的
get(i) 获取元素时,时间复杂度是O(1)
公式:get(i) = 数组的起始位置 + i * 元素占用的内存
构造器
//无参构造器,构造一个容量大小为 10 的空的 list 集合,但构造函数只是给 elementData 赋值了一个空的数组,其实是在第一次添加元素时容量扩大至 10 的。
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//当使用无参构造函数时是把 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 赋值给 elementData。 当 initialCapacity 为零时则是把 EMPTY_ELEMENTDATA 赋值给 elementData。 当 initialCapacity 大于零时初始化一个大小为 initialCapacity 的 object 数组并赋值给 elementData。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
//将 Collection 转化为数组,数组长度赋值给 size。 如果 size 不为零,则判断 elementData 的 class 类型是否为 ArrayList,不是的话则做一次转换。 如果 size 为零,则把 EMPTY_ELEMENTDATA 赋值给 elementData,相当于new ArrayList(0)。
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// 指向空数组
elementData = EMPTY_ELEMENTDATA;
}
}
添加元素–默认尾部添加
//每次添加元素到集合中时都会先确认下集合容量大小。然后将 size 自增 1赋值
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
//判断如果 elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA 就取 DEFAULT_CAPACITY 和 minCapacity 的最大值也就是 10。这就是 EMPTY_ELEMENTDATA 与 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 的区别所在。同时也验证了上面的说法:使用无参构造函数时是在第一次添加元素时初始化容量为 10 的
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//对modCount自增1,记录操作次数,如果 minCapacity 大于 elementData 的长度,则对集合进行扩容,第一次添加元素时 elementData 的长度为零
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
涉及扩容,会消耗性能,但是如果提前指定容量,会提升性能,可以达到与linkedList相当,甚至超越
public void addEffect(){
//不指定下标插入
int length = 10000000;
List al = new ArrayList(length);//指定容量时 效率相当
List ll = new LinkedList();
long start5 = System.currentTimeMillis();
for(int i=0;i <length;i++){
al.add(i);
}
long end5 = System.currentTimeMillis();
System.out.println(end5-start5);
long start6 = System.currentTimeMillis();
for(int i=0;i <length;i++){
ll.add(i);
}
long end6 = System.currentTimeMillis();
System.out.println(end6-start6);
}
执行结果:
912
4237
初始化指定容量,可以减少扩容次数
指定下标添加元素
public void add(int index, E element) {
rangeCheckForAdd(index);//下标越界检查
ensureCapacityInternal(size + 1); //同上 判断扩容,记录操作数
//依次复制插入位置及后面的数组元素,到后面一格,不是移动,因此复制完后,添加的下标位置和下一个位置指向对同一个对象
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;//再将元素赋值给该下标
size++;
}
时间复杂度为O(n),与移动的元素个数正相关
指定下标添加元素,下表越靠前,需要移动的元素越多
扩容
private void grow(int minCapacity) {
int oldCapacity = elementData.length;//获取当前数组长度
int newCapacity = oldCapacity + (oldCapacity >> 1);//默认将扩容至原来容量的 1.5 倍
if (newCapacity - minCapacity < 0)//如果1.5倍太小的话,则将我们所需的容量大小赋值给newCapacity
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)//如果1.5倍太大或者我们需要的容量太大,那就直接拿 newCapacity = (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE 来扩容
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);//然后将原数组中的数据复制到大小为 newCapacity 的新数组中,并将新数组赋值给 elementData。
}
扩容:老的数组拷贝一份到新的容量的数组里,elementData指向新的数组
删除元素
public E remove(int index) {
rangeCheck(index);//首先会检查 index 是否合法
modCount++;//操作数+1
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)//判断要删除的元素是否是最后一个位,如果 index 不是最后一个,就从 index + 1 开始往后所有的元素都向前拷贝一份。然后将数组的最后一个位置空,如果 index 是最后一个元素那么就直接将数组的最后一个位置空
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; //让指针最后指向空,进行垃圾回收
return oldValue;
}
//当我们调用 remove(Object o) 时,会把 o 分为是否为空来分别处理。然后对数组做遍历,找到第一个与 o 对应的下标 index,然后调用 fastRemove 方法,删除下标为 index 的元素。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//fastRemove(int index) 方法和 remove(int index) 方法基本全部相同。
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null;
}
迭代器 iterator
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // 代表下一个要访问的元素下标
int lastRet = -1; // 代表上一个要访问的元素下标
int expectedModCount = modCount;//代表对 ArrayList 修改次数的期望值,初始值为 modCount
//如果下一个元素的下标等于集合的大小 ,就证明到最后了
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();//判断expectedModCount和modCount是否相等,ConcurrentModificationException
int i = cursor;
if (i >= size)//对 cursor 进行判断,看是否超过集合大小和数组长度
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;//自增 1。开始时,cursor = 0,lastRet = -1;每调用一次next方法,cursor和lastRet都会自增1。
return (E) elementData[lastRet = i];//将cursor赋值给lastRet,并返回下标为 lastRet 的元素
}
public void remove() {
if (lastRet < 0)//判断 lastRet 的值是否小于 0
throw new IllegalStateException();
checkForComodification();//判断expectedModCount和modCount是否相等,ConcurrentModificationException
try {
ArrayList.this.remove(lastRet);//直接调用 ArrayList 的 remove 方法删除下标为 lastRet 的元素
cursor = lastRet;//将 lastRet 赋值给 curso
lastRet = -1;//将 lastRet 重新赋值为 -1,并将 modCount 重新赋值给 expectedModCount。
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
remove 方法的弊端。
1、只能进行remove操作,add、clear 等 Itr 中没有。
2、调用 remove 之前必须先调用 next。因为 remove 开始就对 lastRet 做了校验。而 lastRet 初始化时为 -1。
3、next 之后只可以调用一次 remove。因为 remove 会将 lastRet 重新初始化为 -1
不可变集合 Collections.unmodifiableList
// Collections.unmodifiableList可以将list封装成不可变集合(只读),但实际上会受原list的改变影响
public void unmodifiable() {
List list = new ArrayList(Arrays.asList(4,3,3,4,5,6));//缓存不可变配置
List modilist = Collections.unmodifiableList(list);//只读
modilist.set(0,1);//会报错UnsupportedOperationException
//modilist.add(5,1);
list.set(0,1);
System.out.println(modilist.get(0));//打印1
}
Arrays.asList
public void testArrays(){
long[] arr = new long[]{1,4,3,3};
List list = Arrays.asList(arr);//基本类型不支持泛型化,会把整个数组当成一个元素放入新的数组,传入可变参数
System.out.println(list.size());//打印1
}
//可变参数
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
基本类型不支持泛型化,会把整个数组当成一个元素放入新的数组,传入可变参数,因此size打印结果是1
如下图:传入的是一个二维数组

public void testArrays(){
// 包装类型
Long[] arr = new Long[]{1l,4l,3l,3l};
List list = Arrays.asList(arr);/
System.out.println(list.size());//打印
}
如下图,传入的是一个一维数组

什么是fail-fast?
fail-fast机制是java集合中的一种错误机制。
当使用迭代器迭代时,如果发现集合有修改,则快速失败做出响应,抛出ConcurrentModificationException异常。
这种修改有可能是其它线程的修改,也有可能是当前线程自己的修改导致的,比如迭代的过程中直接调用remove()删除元素等。
另外,并不是java中所有的集合都有fail-fast的机制。比如,像最终一致性的ConcurrentHashMap、CopyOnWriterArrayList等都是没有fast-fail的。
fail-fast是怎么实现的:
ArrayList、HashMap中都有一个属性叫modCount,每次对集合的修改这个值都会加1,在遍历前记录这个值到expectedModCount中,遍历中检查两者是否一致,如果出现不一致就说明有修改,则抛出ConcurrentModificationException异常。
底层数组存/取元素效率非常的高(get/set),时间复杂度是O(1),而查找(比如:indexOf,contain),插入和删除元素效率不太高,时间复杂度为O(n)。
插入/删除元素会触发底层数组频繁拷贝,效率不高,还会造成内存空间的浪费,解决方案:linkedList
查找元素效率不高,解决方案:HashMap(红黑树)